技術ネタだけど技術がわからない人にもわかるように書こうと思う。
まず、結論からいこう。これ、なんだと思うだろうか?
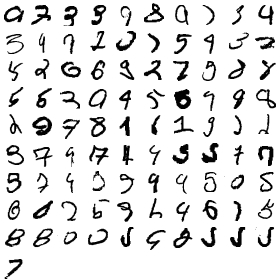
これは、手描きで書かれた数字(0〜9)で、今のところ最高レベルの精度を出すアルゴリズムを使って正しく認識できなかったものの一覧である。
人工知能(機械学習)の研究のベンチマークとして、人間が書いた0〜9の数字をコンピュータが正しく認識できるかというのがある。そういう手書きの数字を集めたデータベースがMNIST Databaseとして公開されている。実際のデータを見てみると、汚い字が多いし、日本人より表記の揺れ幅が大きいと思う。
で、上の認識失敗データを見ると、コンピュータさん、あんた悪くないよ、って気分になる。(普通に読める字もあるけれど)
ここで使われているアルゴリズムはConvolutional Neural Networkと呼ばれてるもので、ここにあるチュートリアルをちょっと改変して出力した。認識に失敗したのは、評価データ1万件中91件のみ(つまり認識失敗率0.91%!)で、上図は失敗したもののすべてである。(正確にいうと、世界最先端ではもっと精度を上げることもできるのだが、簡単に手に入るコードで手もとのPCで簡単に実験できる範囲だとこの程度の精度)
一方最新のアルゴリズムで認識できるようになる文字というのも気にったので、上記チュートリアル上のLogistic Regression(失敗率7.5%)で失敗したけどもConvolutional Neural Networkで成功したものの一覧も作ってみた。(これは網羅的ではなく、一部のみ)
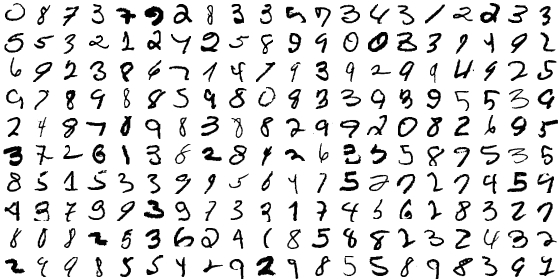
かなりがんぱってるなあ。やっぱりコンピュータさん、悪くない。
再現方法
以下は技術がわかる人向け。
Convolutional Neural Networkでの失敗ケース一覧を出力する方法を以下に示す。もとのチュートリアルのコードをすべてコピーして改変しようかと思ったのだが、ライセンス条項読んでみるといろいろと微妙っぽいので、差分だけを示すことにする。
まずチュートリアルにある以下のファイルをダウンロードして同一ディレクトリに置く。
- http://deeplearning.net/tutorial/code/logistic_sgd.py
- http://deeplearning.net/tutorial/code/mlp.py
- http://deeplearning.net/tutorial/code/convolutional_mlp.py
そしてここにおいてあるパッチを当てる。
そしてconvolutional_mlp.pyを実行すれば終了。(結構時間がかかるので注意)
ピンバック: memo@20150121neblog